这是经过整理和改写后的版本,保持了技术细节完整,同时逻辑更清晰、叙述更流畅,适合科技新闻、学术解读或行业报道使用:在人工智能与机器人技术迅猛发展的背景下,视觉—语言—行动(VLA)模型被广泛认为是构建通 ...
|
这是经过整理和改写后的版本,保持了技术细节完整,同时逻辑更清晰、叙述更流畅,适合科技新闻、学术解读或行业报道使用: 在人工智能与机器人技术迅猛发展的背景下,视觉—语言—行动(VLA)模型被广泛认为是构建通用机器人系统的核心。然而,现有的 VLA 模型(如 OpenVLA、RT-2 等)在应对复杂非结构化环境时仍存在显著短板:空间感知能力不足。它们主要依赖 2D RGB 图像作为视觉输入,导致在三维空间中难以准确判断物体的深度和位置,从而影响操作精度和任务完成率。
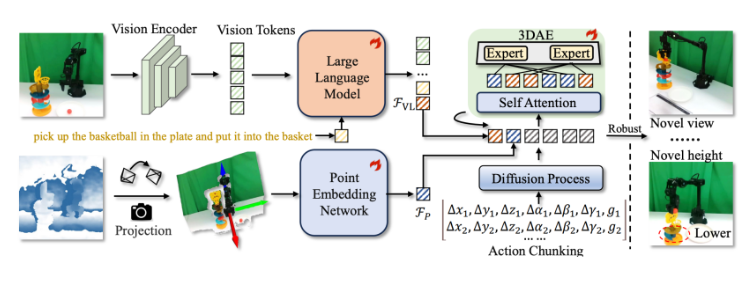
为突破这一瓶颈,原力灵机的研究团队推出了全新的 VLA 框架——GeoVLA。该框架在保留现有视觉—语言模型(VLM)强大预训练能力的同时,采用创新的双流架构,将三维几何感知能力引入机器人系统。GeoVLA 的核心设计包括两个关键模块:专用点云嵌入网络(PEN)和空间感知动作专家(3DAE),使机器人能够真正“看清三维空间”,从而实现更精准的任务执行。 GeoVLA 的设计理念在于任务解耦:VLM 专注于识别“是什么”,点云网络专注于判断“在哪里”。整个端到端框架由三个协同工作的核心组件构成:语义理解流、几何感知流和动作生成流。这种结构不仅提升了机器人在复杂环境下的操作精度,也为不同任务类型提供了高度适应性。
在实验表现上,GeoVLA 展现了显著优势。在 LIBERO 基准测试中,其任务成功率高达 97.7%,全面超越了此前的 SOTA 模型。在更加复杂的物理仿真测试(如 ManiSkill2)中,GeoVLA 仍保持出色表现,即便面对复杂物体组合和多视角变化,其成功率仍然较高。此外,GeoVLA 在分布外场景中的鲁棒性尤为突出,展示了其在面对未知环境和不确定条件下的强大适应能力。 这一突破不仅解决了传统 VLA 模型的空间盲点,也为智能机器人在现实世界中的应用打开了新可能。从工业自动化到服务型机器人,GeoVLA 的出现意味着机器人在三维空间的理解能力将迈上新的台阶,为未来智能机器人的普及与发展奠定坚实基础。 如果需要,我可以帮你再写一个精简快讯版(300 字以内),方便用于科技媒体或公众号推送,同时保留核心亮点和技术突破感。 |


官方手机版

微信公众号

商务合作



评论