|
微软正式宣布开源轻量级实时文本转语音模型 VibeVoice-Realtime-0.5B,这款仅 0.5B 参数的模型实现了 300 毫秒级实时开声,同时支持长达 90 分钟的连续语音生成,无卡顿、不失真,彻底打破了 “轻量模型难兼顾速度与长文本处理” 的行业痛点。目前模型已通过 GitHub 开源仓库免费开放,开发者可直接获取并部署,适配端侧设备与云端服务等多场景需求。
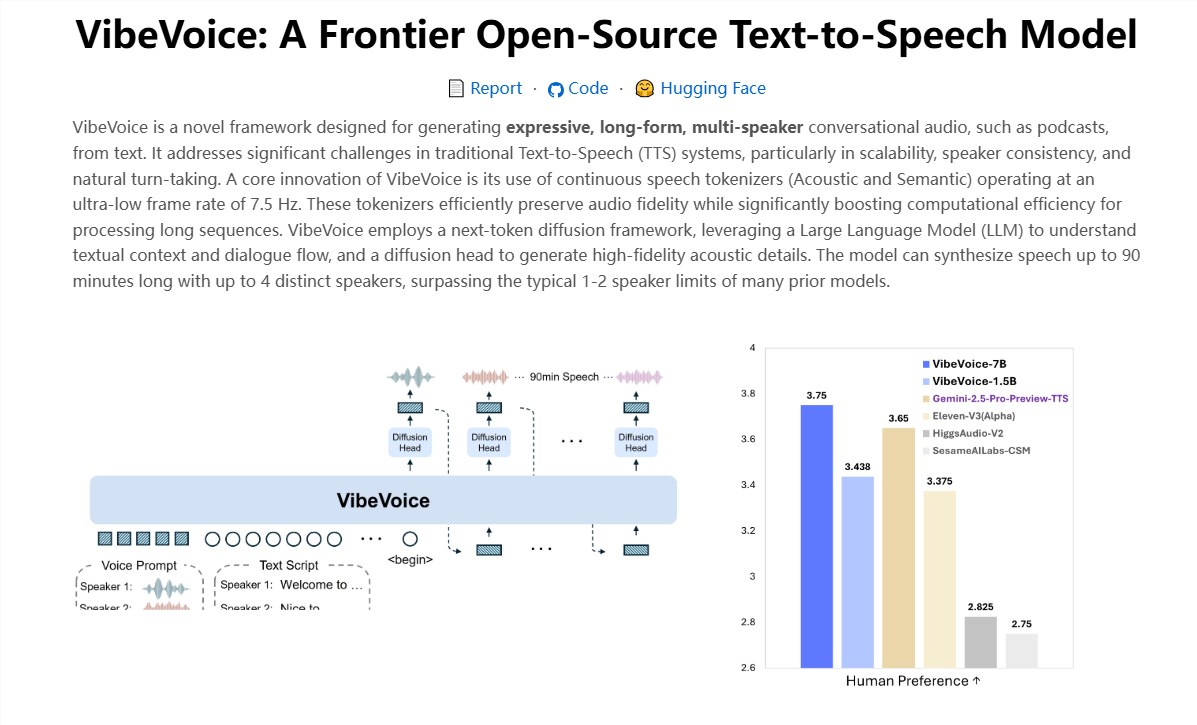
VibeVoice-Realtime-0.5B 定位为 “端侧友好型实时语音合成模型”,核心优势在于 “轻量参数 + 超强性能” 的极致平衡。与传统大参数量语音模型不同,它以仅 0.5B 的参数规模,实现了主流 10B 级模型的核心能力,尤其适合对延迟、算力有严格限制的场景。 “这款模型重新定义了轻量 TTS 的性能上限 —— 我们用创新架构让小模型也能具备实时响应与长文本处理能力,降低开发者在语音交互场景的应用门槛。”—— 微软研究院技术负责人
- 模型推理延迟低至 300 毫秒,远超行业 1 秒级平均水平,达到 “文本输入即语音输出” 的丝滑体验。
- 采用流式推理架构,支持文本分片输入,边输入边合成,长文本场景下无需等待全量文本加载。
- 适配实时对话场景,如智能助手、在线客服等,大幅提升交互自然度。
- 支持最长 90 分钟连续语音生成,过程中保持语调一致、风格稳定,无卡顿或失真现象。
- 原生支持多角色语音合成,单次推理可驱动 4 个不同角色自然对话,各角色音色、语调辨识度持续在线。
- 采用自回归上下文反馈机制,生成过程中实时关联前文内容,确保长对话逻辑连贯、衔接自然。
- 具备智能情感解析能力,可基于文本语义自动识别情绪倾向,映射为愤怒、兴奋、歉意等细腻语调。
- 原生支持中英文双语合成,英文语音自然度表现突出,中文保持高连贯性与高保真度。
- 画面简洁、人物突出、文风平实直接,避免复杂元素干扰,同时支持屏蔽孩子敏感的内容;
- 语音质量达专业水准,UTMOS 自然度评分高达 4.181,远超同参数级模型。
- 紧凑架构设计适配终端设备,可在 CPU 上完成推理,支持手机、笔记本、树莓派等边缘设备部署。
- 无需高额算力支持,开发者通过常规硬件即可完成模型调试与应用开发,大幅降低落地成本。
VibeVoice-Realtime-0.5B 的性能突破源于底层技术创新,构建了 “高效压缩 + 精准生成” 的双核心架构: - 采用连续语音 tokenizer 设计,将 24kHz 高保真音频压缩 3200 倍,帧率仅 7.5Hz,相比主流 Encodec 模型压缩率提升 80 倍。
- 压缩过程中完整保留音频细节与语义信息,重建音质不受影响,为长文本处理奠定效率基础。
- 融合大型语言模型(LLM)与 next-token diffusion 框架,前端通过 LLM 理解文本上下文与对话逻辑,后端通过扩散解码器生成高保真声学细节。
- 训练过程中逐步将上下文窗口从 4K 扩展至 65K tokens,确保长序列处理时的连贯性与一致性。
- 主观评测中,在真实感、丰富度与综合偏好三大维度超越谷歌 Gemini 2.5 Pro、ElevenLabs v3 等顶尖模型。
- 客观指标表现优异,中文测试字错率(CER)仅 1.16%,说话人相似度(SIM)达 0.744,语音质量指标(PESQ)达 3.068。
- 开发者可通过微软官方 GitHub 仓库(含社区维护分支)下载模型权重与源码,支持 PyTorch、ONNX 等框架。
- 提供 OpenAI 兼容 API,可通过简单配置搭建本地服务,支持批量生成与实时调用两种模式。
- 部署要求:Python 3.8+,基础依赖包括 torch、torchaudio 等,GPU(可选)可加速推理,无强制硬件要求。
- 模型基于 MIT 许可证开源,允许商业应用与二次开发,但禁止用于语音 impersonation、虚假信息传播等违规场景。
- 目前仅支持中英文,其他语言可能存在精度不足问题,暂不支持语音重叠生成与背景音效添加。
这款轻量化实时语音模型可广泛应用于各类场景: - 内容创作:播客制作、有声书生成、虚拟访谈录制,支持多角色对话自动化生产。
- 智能交互:智能助手、车载语音、IoT 设备语音响应,提供低延迟自然交互体验。
- 服务领域:在线客服、智能导航、实时翻译,适配连续对话与长语音播报需求。
- 开发工具:为开发者提供低成本实时 TTS 解决方案,加速语音交互类应用落地。
微软表示,未来将持续迭代模型,计划推出 7B 参数版本,进一步提升低延迟交互性能与高保真度,同时扩展多语言支持与功能边界。VibeVoice-Realtime-0.5B 的开源,为中小开发者与企业提供了高性能、低成本的实时语音技术选择,推动语音合成技术在更多场景的普及应用。 要不要我帮你整理一份VibeVoice-Realtime-0.5B 快速部署教程,包含环境配置、API 调用示例与常见问题排查,方便你快速上手使用? |






评论