英伟达研究团队近期公布了其最新成果——PersonaPlex-7B-v1 全双工语音到语音对话模型。该模型突破了以往语音助手必须“等用户说完再回应”的单向交互范式,通过同时感知与生成语音,让人机交流更接近人与人之间的自 ...
|
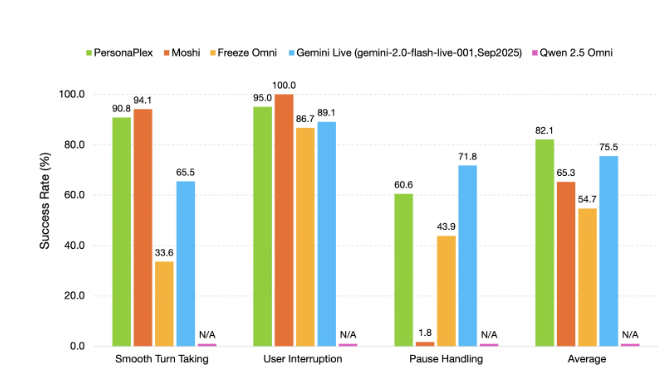
英伟达研究团队近期公布了其最新成果——PersonaPlex-7B-v1 全双工语音到语音对话模型。该模型突破了以往语音助手必须“等用户说完再回应”的单向交互范式,通过同时感知与生成语音,让人机交流更接近人与人之间的自然对话节奏与临场感。
相较于以往依赖 ASR(语音转文本)→ LLM(大语言模型)→ TTS(文本转语音) 多模块串联的传统方案,PersonaPlex 采用了一种更为激进的设计思路:以单一 Transformer 架构端到端完成语音的理解与生成。这种一体化路径省去了中间转换环节,大幅压缩了系统响应时间,同时让模型能够自然应对对话中的插话、语音重叠以及即时反馈等复杂情况。直观来看,它更像人与人交谈——在输出内容的同时仍保持持续“倾听”,即便被突然打断,也能迅速调整并作出回应。 在个性化能力上,PersonaPlex 同样表现突出。模型支持通过语音与文本的双重条件进行引导,不仅可以设定 AI 的人物角色与背景,还能细粒度控制其声音特征、语调和表达风格。据了解,英伟达在训练过程中融合了大量真实通话样本与精心构造的合成场景,使模型既保留了自然对话的语言习惯,又能够严格遵循特定行业或业务场景的规则约束。现有评测结果表明,PersonaPlex-7B-v1 在对话连贯性与任务完成效率方面,已整体超越多数主流的开源与闭源语音对话系统。
|


官方手机版

微信公众号

商务合作


评论