|
为响应香港特别行政区政府全力发展人工智能(AI)为关键产业的策略,香港科技大学(科大)今日正式成立冯诺依曼研究院(Von Neumann Institute),整合具身智能、生成式AI及先进超级运算等技术,推动跨学科协作,促进新质生产力,以迎接AI世代。 冯诺依曼研究院由计算机视觉与AI领域知名专家、科大计算机科学及工程学系讲座教授兼独角兽企业思谋集团创始人贾佳亚教授领导,并以「计算机之父」约翰·冯·诺依曼命名。约翰·冯·诺依曼为著名的计算机科学家,其开创的「冯诺依曼架构」对当今的AI算法影响深远。凭借科大在AI领域的坚实基础及贾教授广泛的产业网络,研究院将致力于构建完整的AI生态系统,加强产学研合作,并通过中学拓展计划,培育新一代AI人才。
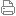
Vonnex机械人展现AI突破 出席研究院开幕礼的主礼嘉宾包括香港特别行政区财政司司长陈茂波、匈牙利驻香港总领事柯泰安 (Dr. Pál Kertész) 及香港投资管理有限公司(港投公司)行政总裁陈家齐,以及科大校董会主席沈向洋教授、校长叶玉如教授及首席副校长郭毅可教授等。其中,贾教授团队研发的AI机械人Vonnex更参与揭幕仪式,展现了其流畅的操作及多模态感知系统,更能同时处理视觉、触觉及声音等信息,彰显机械人技术的潜能。
财政司司长陈茂波先生在致开幕辞中表示:“特区政府相信人工智能蕴藏巨大的潜力。我们的目标是通过‘AI+’策略,将AI融入各行各业。冯诺依曼研究院汇聚了科大、思谋集团及港投公司等多方人才与资源,集合卓越的学术水平、坚实的基础研究、丰富的业界经验,更拥有庞大的企业与投资者网络。我们期望研究院能成为开拓AI应用场景与推动研究成果商业化的平台,为香港不断发展的创科生态系统以及人工智能领域的进步作出贡献。” 港投公司行政总裁陈家齐致辞时说:“港投公司作为代表特区政府的‘耐心资本’,通过支持尖端技术产业化,推动被投企业参与香港的AI研究和落地转化。思谋集团与科大成立研究院,实践了与港投公司签订战略合作协议的承诺,包括与香港高校在产学研合作,培育人才。我期望研究院透过探索AI创新与应用,孵化并培育更多独角兽,构建更完善的AI生态圈。”
沈向洋教授欢迎辞中表示:“科大成立冯诺依曼研究院,是对香港致力发展成国际创新科技枢纽的策略举措。透过结合政策创新、产业需求、资本支持和学术创造力,我们将汇聚世界级的AI人才,并以跨学科合作探索AI的前沿发展。”
聚焦五大AI研究领域 在活动期间,贾佳亚教授指出,研究院将透过整合、协作及资源汇聚,聚焦五大AI关键领域,包括开发新一代多模态AI系统,以处理图像、音频及文本等多样化数据;增强AI逻辑推理能力,建立可信赖的解决方案;开发机器人智能技术,实现模仿人类运动的控制及互动;通过AI驱动的三维(3D)理解与生成,创建贴近现实的虚拟生态系统;以及利用大模型改革医疗保健服务,提升治疗效果。
孕育新一代AI人才 在港投公司的支持下,研究院推出“AI探索者:人工智能学校教育计划”,透过举办讲座、AI及热门科研课堂,以及于科大及思谋集团的实验室进行示范等,旨在激发学生的好奇心,孕育新一代的思想家及创新者,帮助他们为应对未来挑战做好准备,裨益香港社会。出席典礼的圣保禄学校(中学部)及圣保罗男女中学的师生,均已表明有意参与相关计划。
此外,研究院还会培训超过100名博士生,并汇聚不同专业领域的学术人员,为一众科大毕业生装备前沿理论知识,以及实用的业界技能。
|